
Chez Inyulface, nous nous intéressons particulièrement aux enjeux qui touchent les données. Pour les questions autour de la collecte, le traitement, l’exploitation, le partage et la sécurité des données. Aujourd’hui nous vous proposons de découvrir un nouveau concept intéressant pour répondre aux enjeux de collaboration autour des données : le Data Mesh.
Qu’est-ce que le Data Mesh ?
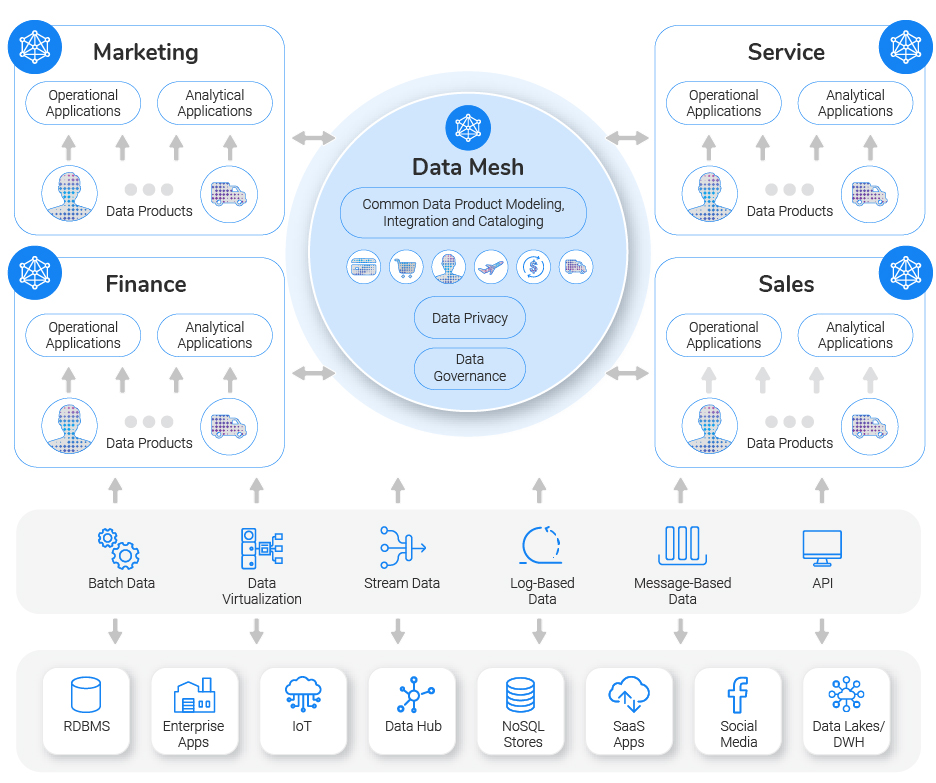
Le Data Mesh ou « maillage de données » n’est pas une technologie mais un cadre de travail pour permettre aux entreprises de mettre la donnée au centre de leur organisation. Avec une approche de décentralisation plutôt que l’approche classique de centralisation des données dans un lac de données (Data Lake) ou entrepôt de données (Data Warehouse). L’idée est plutôt de favoriser la collaboration entre les domaines de l’entreprise, casser les silos de données, en donnant aux « métiers » la responsabilité des données analytiques.
Ce concept relativement récent a été publié en 2019 par l’expert Zhamak Dehghani sur son blog lorsqu’ils travaillait chez Thoughtworks. Depuis il a fondé sa propre société, NextData Technologies. Et il a formalisé le concept de Data Mesh dans un livre publié en mars 2022 chez O’Reilly.
Quels sont les principes fondateurs du Data Mesh ?
Les 4 principes de base du Data Mesh sont :
1-Data as a product : considérer la donnée comme un produit. Ce qui veut dire que la donnée issue d’un domaine ou département peut aussi servir pour les données (produits) d’un autre département.
2-Business domain-driven data ownership : décentraliser et distribuer les responsabilités au plus proche de la donnée, par domaine (métier).
3-Self serve data platfom : une plateforme qui donne un accès direct et autonome aux données en “libre-service”.
4-Federated (Distributed) data governance : la gouvernance des données doit être automatisable, décentralisée, et chaque domaine est responsable. Une démarche qui implique que les pratiques soient normalisées pour que les systèmes soient interopérables entre domaines.
On comprend donc aussi que les équipes domaines gagnent en autonomie et responsabilité vis-à-vis des données. Mais elles doivent être soutenues par une équipe de plateforme de données pour l’utilisation des outils et la mise en place de normes.
Quelle est la différence entre Data Mesh et Data Fabric ?
Il existe de nombreux concepts de gestion de la donnée dans l’entreprise. Celui de “data fabric” (issu du cabinet d’analyste Gartner) pourrait sembler proche du “Data Mesh” mais il est bien différent.
La Data Fabric ou “fabrique de données” est une approche d’architecture technique avec une plateforme centralisée pour accéder aux données. Alors que le Data Mesh est agnostique par rapport aux données et se base plutôt sur des principes organisationnels et métiers.
Quels sont les principaux bénéfices du Data Mesh ?
Le Data Mesh permet de démocratiser les données et l’analytique dans l’entreprise. Il peut également accompagner une migration cloud, ou encore une intégration de données en temps réel. Certaines entreprises s’inspirent aussi de cette approche de “maillage de données” pour des projets IOT et analytique, et des analyses de flux de données.
Parmi les entreprises qui expérimentent déjà avec l’approche Data Mesh : Zalando, Netflix, Intuit, VistaPrint, JPMorgan Chase, PayPal.